The abstracts in the current iteration of the similarity tool were:
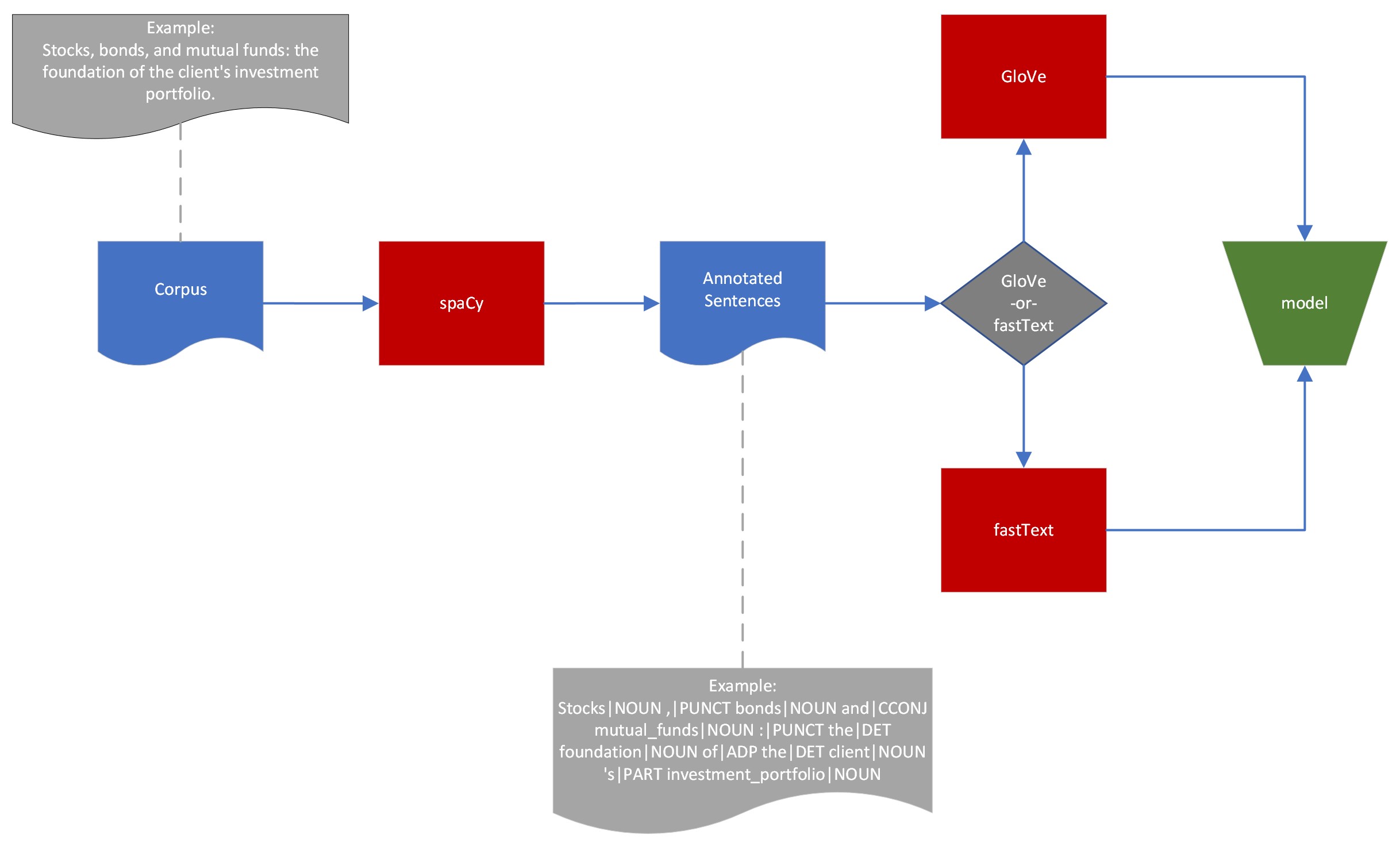
Corpus
The corpus consists of publicly available 8K, 10K, 10Q, SEC-1, SEC-2, SEC-4 official filings for the years 1995, 2000, 2005, 2010, 2015, and 2020.
sense2vec
sense2vec (Trask et. al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. Before training the model, the text is preprocessed with linguistic annotations, to let you learn vectors for more precise concepts. Part-of-speech tags are particularly helpful: many words have very different senses depending on their part of speech, so it’s useful to be able to query for the synonyms of duck|VERB and duck|NOUN separately. Named entity annotations and noun phrases can also help, by letting you learn vectors for multi-word expressions.
fastText
fastText is a library for learning of word embeddings and text classification created by Facebook's AI Research lab. The model allows one to create an unsupervised learning or supervised learning algorithm for obtaining vector representations for words.
GloVe
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
Enter a search term to find the most similar values from across papers from the Financial Economics Network (FEN) on SSRN: